Let’s consider counting events happening in an observation interval with time \(T \in [0,t)\). The count of these events are generated according to a Poisson process with rate \(\lambda\) and observation interval width \(t\), given by \[
f_{\text{Pois}}(k|\lambda t) \equiv \frac{(\lambda t)^k}{k!} e^{-\lambda t}.
\] We can continue our “clinic” example from the Poisson lesson; a Poisson process could be used to describe the number of patients who visit a clinic in a one-hour period. Let’s say that we opened up the clinic in the morning, and we ask ourselves “how long do we have to wait until the first patient arrives?” Mathematically, this would be asking what the value of \(T\) will be when \(k\) increments from 0 to 1.
The probability that we have not yet observed an event by time \(t\) is given by \[
\mathbb{P}(0|\lambda, T = t) = \frac{(\lambda t)^0}{0!} e^{-\lambda t} = e^{-\lambda t}.
\] Notice that we can modify our question from asking about a random variable \(k\) to asking about a random variable \(T\). We then see that these two quantities are the same, but their random variables are different: \[
\mathbb{P}_k(0|T = t, \lambda) = \mathbb{P}_T(T > t|\lambda).
\] In vernacular, we are saying that the probability of observing a count of zero events on or before time \(t\) is the same as the probability that the time of the first event is after (greater than) \(t\).
Because of the logical equivalence of these events, we can say that the probability that the first event (which happens at time \(T\)) hasn’t happened yet (as of time \(t\)) is given by \[
\mathbb{P}(T > t) = e^{-\lambda t}.
\] This is the probability that the first event will happen after time \(t\). Thus, the probability that the first event will happen before the end of our observation interval (which ends at time \(t\)) will be the opposite of this: \[
\mathbb{P}(T \le t) = 1 - e^{-\lambda t}.
\]
Notice that we have just described the cumulative probability function1. As we all remember, the Cumulative Probability Function is the indefinite integral of the Probability Function, so to find a closed form of the Exponential distribution, we take the derivative with respect to the random variable \(t\). So, for \(\lambda,t > 0\), \[
\begin{aligned}
F_T(t|\lambda) &= 1 - e^{-\lambda t} \\
\Longrightarrow f_T(t|\lambda) &= \frac{d}{dt} \left( 1 - e^{-\lambda t} \right) \\
&= - e^{-\lambda t} (-\lambda) \\
\Longrightarrow f_{\text{Exp}}(t|\lambda) &= \lambda e^{-\lambda t}.
\end{aligned}
\]
After all the suffering through theory we’ve done in the last few lessons, the formal theory needed for this lesson is quite light.
5.3.1 Improper Integrals
The Fundamental Theorem of Calculus states that, if \(f\) is a continuous function on a closed interval from \(a\) to \(b\) (inclusive) with anti-derivative \(F\), then \[
\int_a^b f(x) dx \equiv \left[ F(x) \right]_a^b \equiv F(b) - F(a).
\] Notice that this definition requires that the interval include both \(a\) and \(b\). Improper integrals mean that either \(f\) is not continuous over the interval \([a,b]\), or either \(a\), \(b\), or both, are infinite. For many statistical distributions, the bounds of the support of the random variable include \(\infty\) on one side or both. That means that we can’t just take the integral and substitute in \(\infty\) and “call it a day”. For common statistical distributions with unbounded support, there are two cases.
Case 1: The Interval is Open on One Side. If we have either the lower or upper bound of the integral tending to \(\infty\), then we do this: \[
\begin{aligned}
\int_a^{\infty} f(x) dx &= \lim_{\psi\to\infty} F(\psi) - F(a) \\
\int_{-\infty}^b f(x) dx &= F(b) - \lim_{\psi\to -\infty} F(\psi) \\
\end{aligned}
\]
Case 2: The Interval is Open on Both Sides. If we have the lower and upper bound of the integral as the entire Real line, then we split the integral into two “one-sided” improper integrals at some value \(x = a\) and evaluate each separately. That is: \[
\int_{-\infty}^{\infty} f(x) dx = \int_{-\infty}^a f(x) dx\ +\ \int_a^{\infty} f(x) dx.
\] If \(f\) is symmetric around the axis \(x = a\), then this simplifies even further: \[
\int_{-\infty}^{\infty} f(x) dx = 2 \times \int_a^{\infty} f(x) dx.
\] The Normal and Student’s \(t\) distributions are the two most famous distributions with support over the entire Real line, and they are both symmetric around their mean values (\(\mu\) for the Normal and 0 for the Student’s \(t\) distributions).
5.4 Show that this is a Distribution
We recall that \(\lambda, t > 0\), so \(f_{\text{Exp}}(t|\lambda) > 0\). For the total probability, we need to remember that we can reverse the limits of integration,2 and we need to be able to solve an improper integral (described above). Once you have reviewed these concepts, consider \[
\begin{aligned}
\int_{\mathcal{S}(t)} dF(t|\lambda) &= \int_0^{\infty} \lambda e^{-\lambda t} dt \\
&= \lim_{\psi \to \infty} \left[ -\frac{\lambda}{\lambda} e^{-\lambda t} \right]_{t = 0}^{\psi} \\
&= \lim_{\psi \to \infty} \left[ -e^{-\lambda t} (-1) \right]_{\psi}^{t = 0} \\
&= \lim_{\psi \to \infty} \left[ e^{-\lambda t} \right]_{\psi}^{t = 0} \\
&= \left[ e^{\lambda [0]} \right] - \left[ \lim_{\psi \to \infty} e^{-\lambda \psi} \right] \\
&= 1 - 0.
\end{aligned}
\] Therefore, \(f_{\text{Exp}}(t|\lambda)\) is a probability distribution.
5.5 Derive the Moment Generating Function
As with the Poisson Distribution, we will call the nuisance parameter for the MGF \(s\) instead of \(t\), as \(t\) is the random variable of the Exponential Distribution. Recall that the MGF must be defined for \(s\) in an \(\epsilon\)-neighbourhood of 0, for some arbitrarily small \(\epsilon\). This means that, without loss of generality, we can bound \(s\) to be smaller than the rate parameter \(\lambda > 0\) (which we will need below). Thus,
5.6 Method of Moments Estimates from Observed Data
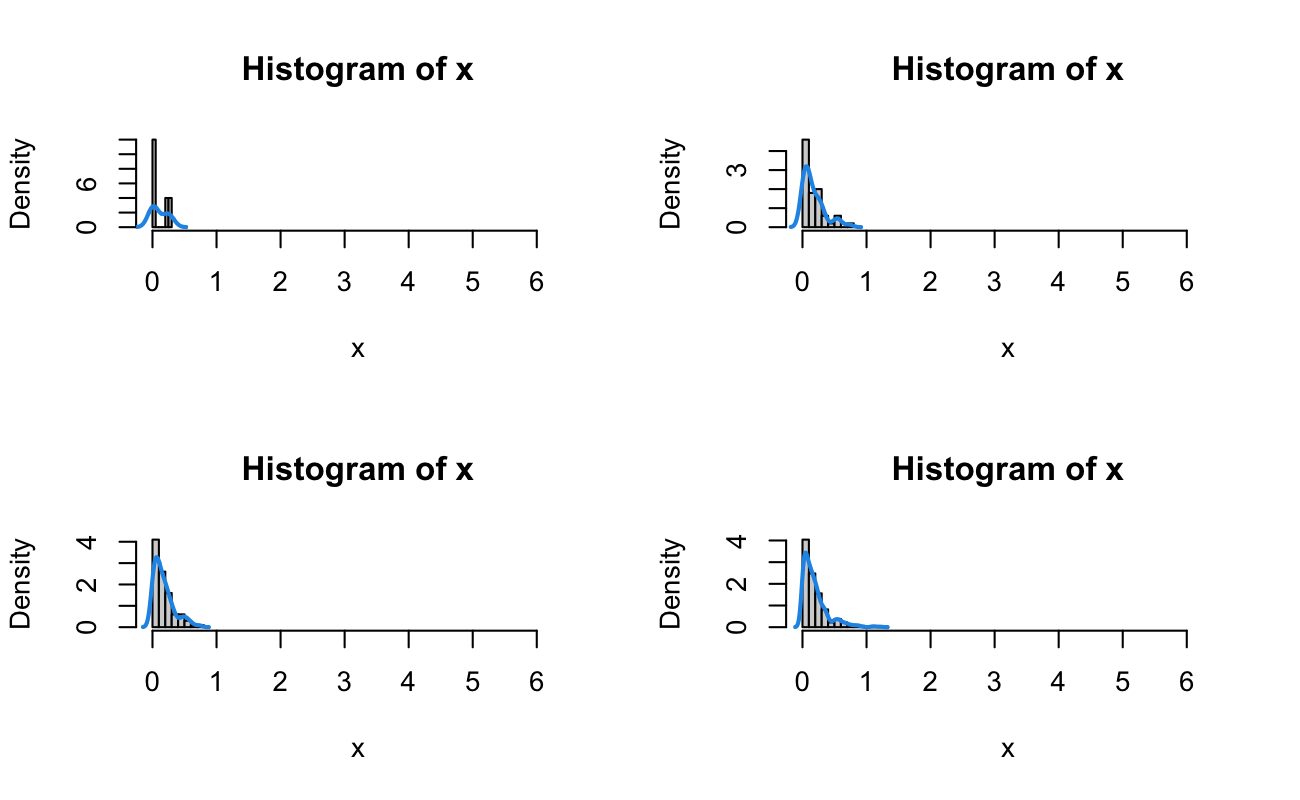
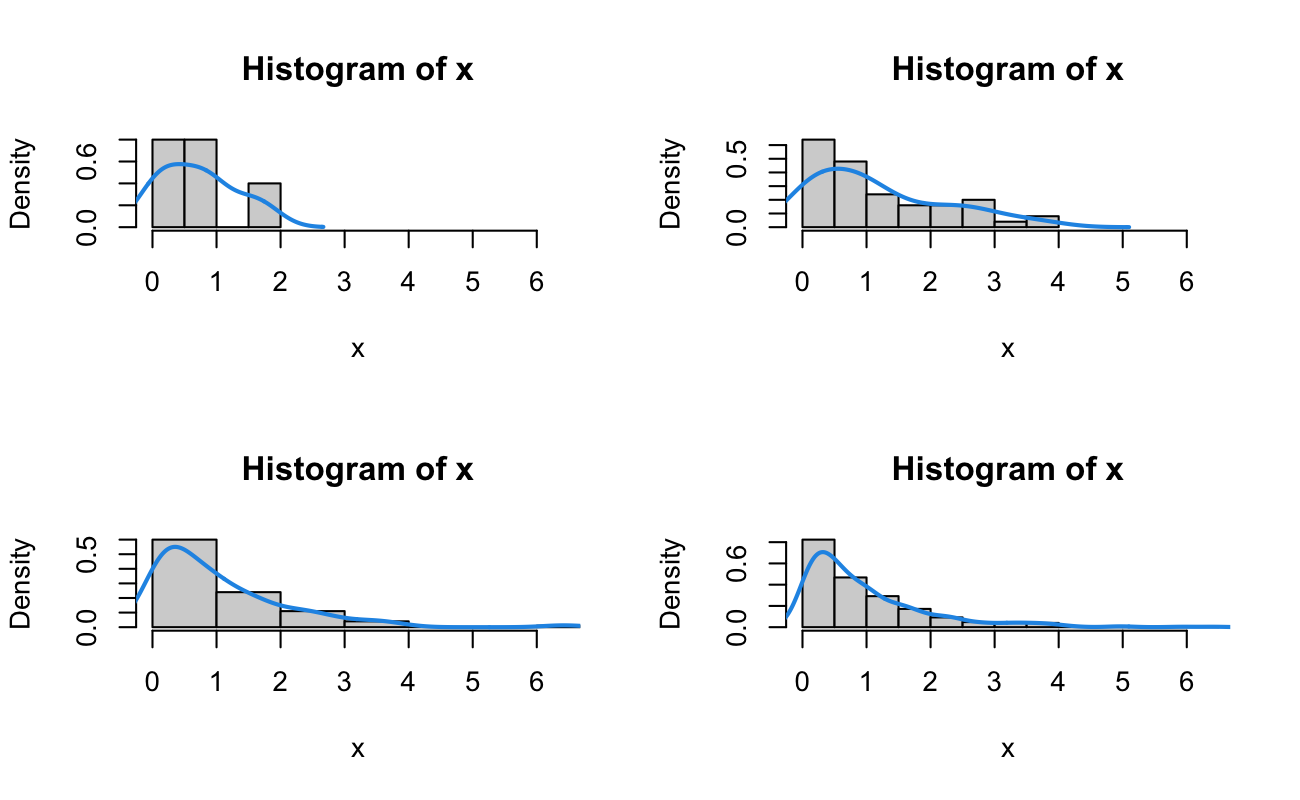
Let’s generate some random data. We continue our “clinic” example, and now we generate 7 “waiting times” until the first patient walks in. For a single experiment, that is, when we first open the clinic, how long will we have to wait for the first patient to arrive? Let’s assume the same rate of \(\lambda = 5\) for one hour that we used in the previous lesson. We can generate data (in fractional hours) by
So, for these 7 independent trials where the waiting times \(T\) have an identical Exponential distribution with rate of 5 patients per hour, we wait 2.2, 0.3, 16.4, 0.1, 12.8, 12.5, 16.6 minutes to see the first patient.
We then have that \(\bar{x} = \frac{1}{\lambda}\) and \(s^2 = \frac{1}{\lambda^2}\), which is an overdetermined system (with \(\hat{\lambda}_{\text{MoM}} = \frac{1}{\bar{t}}\)). For the Exponential Distribution, once we know the mean, then we should also know the variance. For our sample, generated from an Exponential with rate \(\lambda = 5\), \(\hat{\lambda}_{\text{MoM}}\) = 6.892. It’s worth noting that the Method of Moments estimate for this distribution requires a very large number of samples before it is “close” to the true value (the Maximum Likelihood estimator is the same, as we’ll see next).
5.7 Maximum Likelihood Estimators
To estimate a true rate, \(\lambda\), using the likelihood, we collect a set of independent observed times for the first success. That is, \(\textbf{t} = [t_1, t_2, \ldots, t_n] \overset{iid}{\sim} \text{Exp}(\lambda)\). Thus, \[
\begin{aligned}
f_{\text{Exp}}(t|\lambda) &= \lambda e^{-\lambda t} \\
\Longrightarrow \mathcal{L}(\lambda|\textbf{t}) &= \prod_{i = 1}^n \lambda e^{-\lambda t_i} \\
\Longrightarrow \ell(\lambda|\textbf{t}) &= \log \left[ \prod_{i = 1}^n \lambda e^{-\lambda t_i} \right] \\
&= \sum_{i = 1}^n \log \left[ \lambda e^{-\lambda t_i} \right] \\
&= \sum_{i = 1}^n \left[ \log(\lambda) - \lambda t_i \right] \\
&= n\log(\lambda) - \lambda \sum_{i = 1}^n t_i \\
&= n\log(\lambda) - n\lambda\bar{t} \\
\Longrightarrow \frac{\partial}{\partial\lambda} \ell(\lambda|\textbf{t}) &= \frac{\partial}{\partial\lambda} \left( n\log(\lambda) - n\lambda\bar{t} \right) \\
&= \frac{n}{\lambda} - n\bar{t} \\
\Longrightarrow 0 &\overset{\text{set}}{=} \frac{n}{\hat{\lambda}} - n\bar{t} \\
\Longrightarrow n\bar{t} &= \frac{n}{\hat{\lambda}} \\
\Longrightarrow \hat{\lambda} &= \frac{1}{\bar{t}}.
\end{aligned}
\] In order to confirm that this extreme value of the log-likelihood is truly a maxima, we take the second partial derivative: \[
\begin{aligned}
\frac{\partial}{\partial\lambda} \ell(\lambda|\textbf{t}) &= \frac{n}{\lambda} - n\bar{t} \\
&= n\lambda^{-1} - n\bar{t} \\
\Longrightarrow \frac{\partial^2}{\partial\lambda^2} \ell(\lambda|\textbf{t}) &= -n\lambda^{-2} \\
&< 0.
\end{aligned}
\] Hence, \(\hat{\lambda}_{MLE} = \frac{1}{\bar{t}}\).